Good day! I am a Computer Science undergraduate at the National University of Singapore (NUS). This document showcases the contributions I made for a group term project. I hope this shows you my abilities engineering software!
Overview
README is a desktop bookmark manager/RSS feed reader application. README lets users store webpages for offline reading, in addition to subscribing to feeds so that their favourite content is automatically downloaded and delivered to them.
When looking at many other applications on the market for inspiration,
we found a big hole.
Most other applications do not support reading your saved links while offline,
and as such we decided it was a critical feature,
and I was placed in charge of this feature.
However, this requires integrating Storage and Network together,
which lie on opposite ends of the design.
This makes it a technically challenging feature,
interacting with most other components such as the Model.
Thus, the bulk of my contributions lie in figuring out a good way to architect the overall design so that it is easy to support this feature.
Summary of contributions
Given below are contributions that I made to this application. |
Major enhancement: Offline mode
I implemented a local data store that stores articles so that they can be retrieved later even while offline.
-
Justification: Dramatically makes the application more useful for users who are often on the go, without an internet connection.
-
Highlights:
-
Automatic download: A copy of every article saved to the reading list is saved so it can be viewed offline.
-
Refresh command: When pages get out of date, the user can execute a command to download an updated copy.
-
Absolute link conversion: Ensures most pages will continue to work properly even while offline by converting relative links that stop working when viewing pages offline, to absolute links that work everywhere.
-
Minor enhancement: Adding all variants of commands
Many commands like refresh and archive (by Jonathan)
only operate on single entries.
I added new commands such as refreshall and archiveall
that operate on all currently displayed entries for ease of use.
Code contributed:
For an overview of all of code contributed by me, refer to the CS2103T module dashboard!
Otherwise, refer to the links below to relevant pull requests for each enhancement. Some enhancements are done over several pull requests, so all relevant ones are linked.
-
Offline mode
-
allcommands: PR #190
Other contributions:
-
Project management:
-
Set up issue tracker
-
Set up Travis, AppVeyor, Codacy, and Coveralls status checks.
-
Set up Branch Protection on
master
-
-
Enhancements to existing features:
-
Automatically scroll the list panel to the location of the added entry when adding links.
-
Automatically fill in a default tag when subscribing to a feed.
-
-
Community:
-
Regularly review pull requests (PR). While we mainly review through our private chat, some are done directly on Github. See here for the complete list.
-
Otherwise, look below for PRs with non-trivial comments!
-
Reported bugs and gave suggestions for another group’s project, The Infinity Machine:
-
-
Tools:
-
Integrated a third party tool (PlantUML) to the project (#18)
-
Contributions to the User Guide
Given below are sections I contributed to the User Guide. They showcase my ability to write documentation targeting end-users. |
Archiving all displayed entries: archiveall
If you want to archive many entries at the same time,
you can make use of this command to move all the currently displayed entries to the archive,
removing all entries' downloaded content at the same time.
By using a find command first before executing archiveall,
you can archive parts of your reading list by a search criteria.
Format: archiveall
Examples:
-
Archive all entries in the reading list
-
list -
archiveall
-
-
Archive all entries tagged “infoTheory” (you may refer to the figures below)
-
list -
find t/infoTheory -
archiveall -
list
-
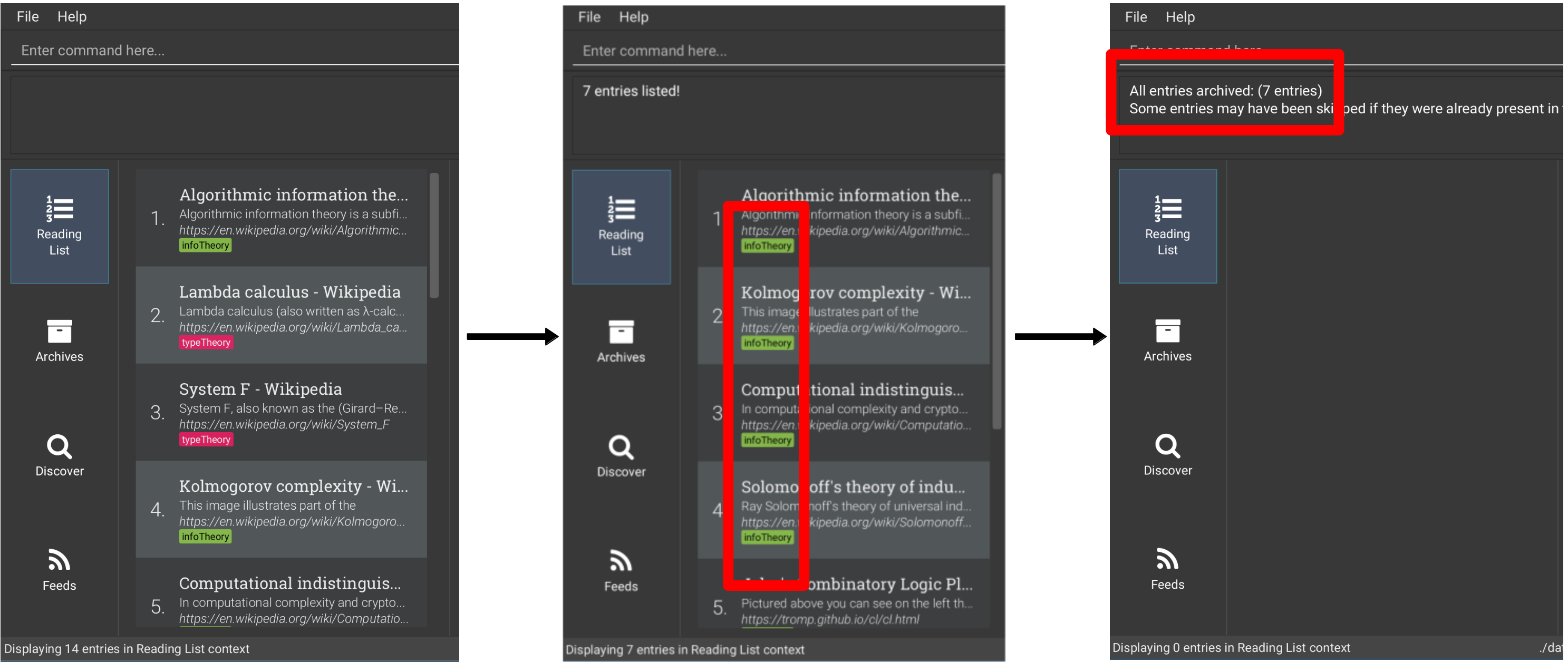
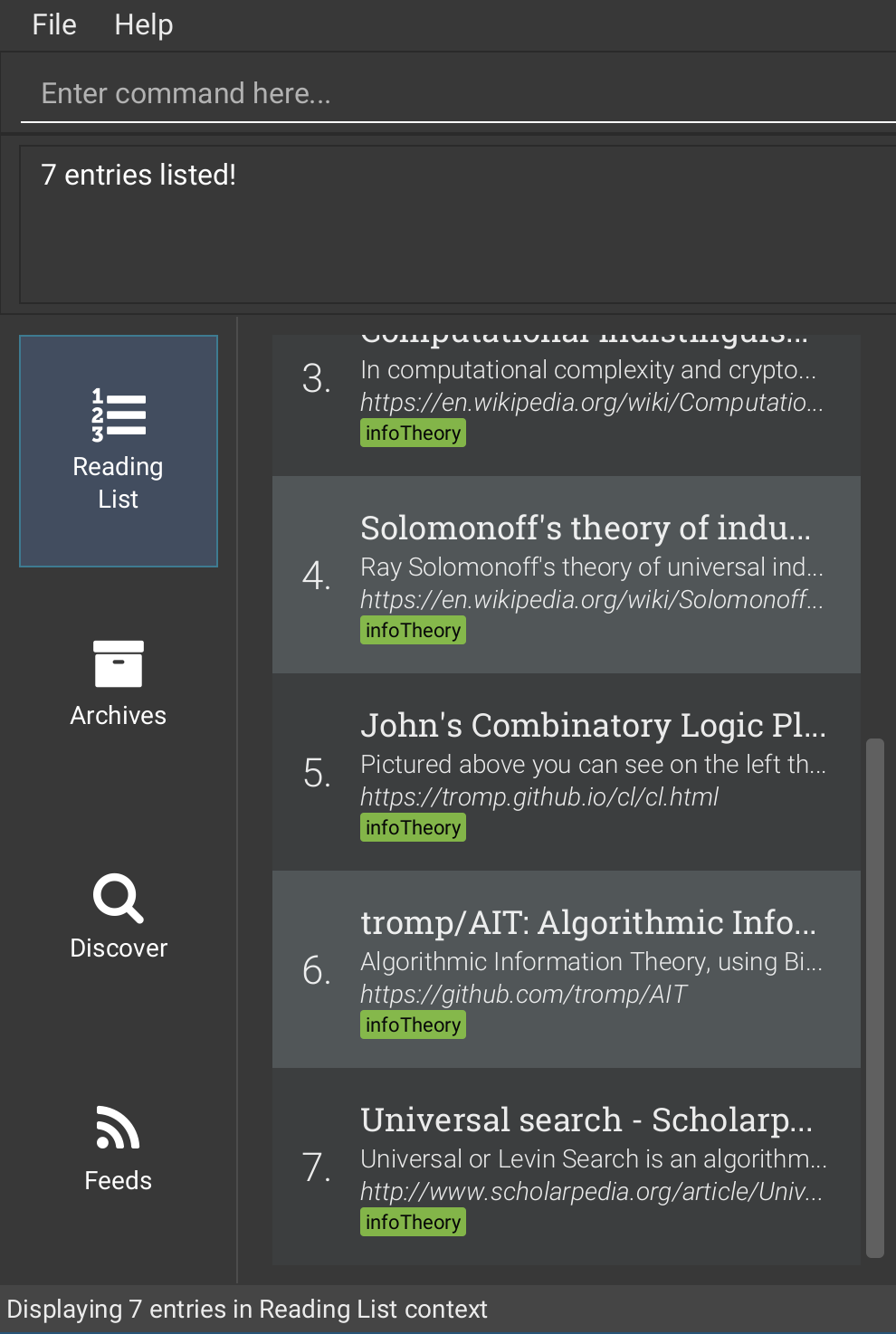
Refreshing an entry: refresh
If you added an entry a long time ago and you think that the saved page might be outdated,
you can fetch the most updated version from the internet by using this command.
This is helpful for pages such as Wikipedia, which may change often!
See the refreshall command which may be useful to use if you need to refresh a large number of entries at the same time.
Format: refresh INDEX
Examples:
-
Refresh the content of the 2nd entry in the reading list.
-
list -
refresh 2
-
Contributions to the Developer Guide
Given below are sections I contributed to the Developer Guide. They showcase my ability to write technical documentation and the technical depth of my contributions to the project. |
Network design
As many components have to make network calls
to retrieve resources from the Internet,
we decided to centralise it in a "singleton" class named Network.
The following sections describe the different design patterns we considered
and their pros and cons.
Design Considerations
This component is depended on by the following components:
-
AddCommand (when adding articles so that they can be saved to disk)
-
BrowserPanel (when viewing articles or feeds)
-
Feeds management system (for fetching subscriptions, or saving feeds)
Thus, our design needs to take into consideration how it is going to be used.
Because it’s possible that the settings we use to fetch resources may need to be changed over time (e.g. timeouts, request headers, cookies, etc.), we should centralise the design to one component so that these can easily be changed. Obviously, this component should be easily accessible from all the components listed above. Finally, the interface for this component should be general and apply to all use cases because we have a large mix of possible requests: articles, feeds, or other resources.
The only way we can make this component easily accessible is to make it global. However, there are a couple of ways to design a global component. The following sections describe the patterns considered.
Static class pattern (chosen pattern)
This pattern is to create a new class named Network.
This class is abstract so it cannot be instantiated,
and all its methods are marked private.
Pros
-
Convenient access to the network
-
Good cohesion: everything with networking details in one file
-
Easy to write and subsequently modify
Cons
-
Global variable, which encourages coupling with everything else in the codebase
Singleton pattern
This pattern is very similar to the pattern above.
We create a new class named Network,
and a static getter method that returns a single instance of Network.
This allows us the flexibility of working with objects
rather than with static methods.
Pros
-
Convenient access to the network
-
Good cohesion: everything with networking details in one file
-
A little bit harder to write, as we need to include the Singleton logic, but still easy
-
Objects allow you to perform dependency-injection, so the calling class can obtain the
Networkinstance and pass it down -
Has the option of extending the class to possibly allowing multiple instances in the future
Cons
-
More work than the static class pattern
Ad-hoc aka no pattern
We could also choose to directly call the network API
from whatever calling methods would have called Network before.
This is the simplest "pattern" as it involves not writing any code.
Pros
-
No need to write any code
-
No coupling since there’s no code
Cons
-
Bad cohesion: networking related code will be thrown all over the codebase. If we were to switch to using a different API or needing to change a particular detail in how the network API is called, then we would need to change them in all the places where the network API got called.
Comparison of methods and why we went with the static class pattern
Ranking the patterns from least effort to most effort, we have ad-hoc being the easiest, followed by static class, and finally singleton.
Generally, the less code, the better. This is usually the primary consideration. This means if there are two patterns where both meet some minimum quality standard but one takes more effort, we should go with the one that takes less effort to write.
We did not choose the ad-hoc pattern because we anticipate future changes to the networking code as we take into account more details like timeouts, asynchronicity, cookies, etc. In other words, this led us to prioritise good cohesion in our desired pattern.
However, aside from this, both singleton and static class pattern
have roughly the same benefits.
We do not yet need to consider things like dependency inversion
because Network calls are decidedly a very global concept
which makes it less applicable.
Using the singleton pattern would have improved testability of our code,
but it would have required rewriting many of our classes
to use dependency inversion,
and this makes the code more complex.
So this is why we went with the static class pattern, which has effectively the same benefits as singleton after ruling out dependency inversion, and the static class pattern is easier to write than the singleton pattern.
Asynchronous network calls
As the entirety of addressbook-level4 (AB4) is written synchronously,
it is a major undertaking to convert AB4 to use asynchronous (async) network calls.
We did a small scale experiment to see how async might be done by making
the select command download un-downloaded articles in the background.
Here is a sequence diagram showing how the interaction works:
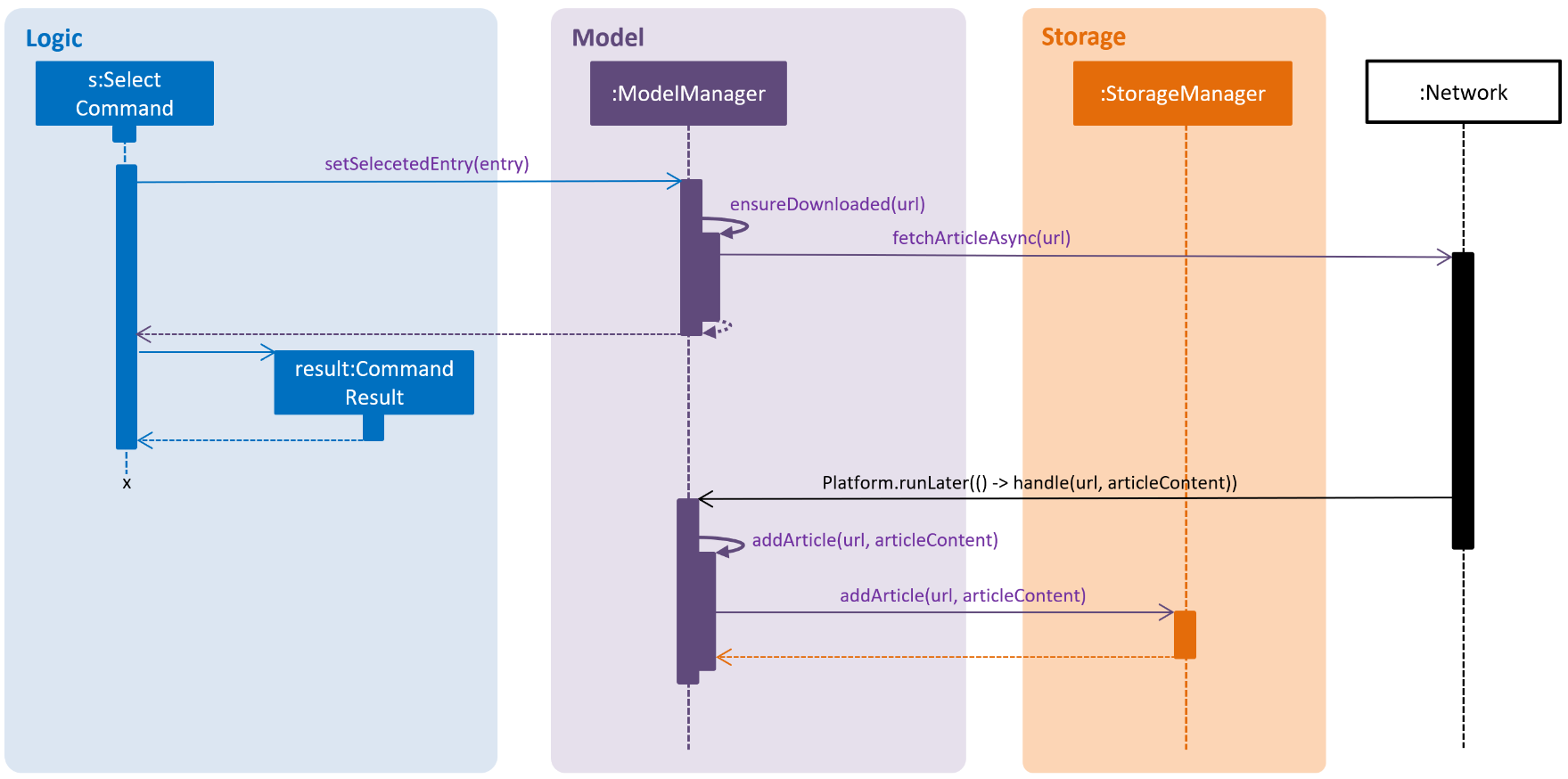
Notice that when returning from the async network call,
we wrap our code in Platform.runLater(…) to ensure that the rest of the
execution is done on the JavaFX Application Thread.
This helps to prevent certain race conditions from potentially ruining the model.
However, in the process of implementing this, we found that it made testing this unreliable as we could no longer be sure when the command has "truly" finished executing. Thus, we decided to defer the conversion of the rest of the AB4 to async to the v2.0 milestone.
Storage component
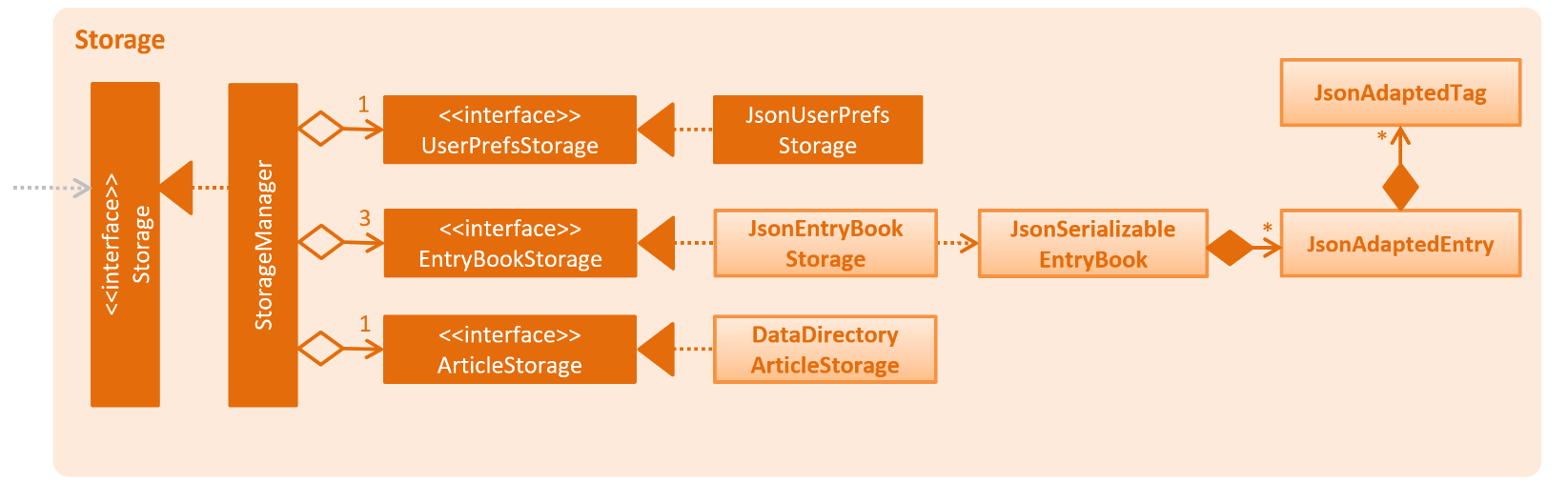
API : Storage.java
The Storage component,
-
can save
UserPrefobjects, andEntryBookdata (for Reading List, Archives, and Feeds) in json format and read it back. -
can save .html articles in a data directory as individual files. The article contents are only read when required by the user.
Unlike the UserPref and EntryBook data, we don’t store the articles in a flat file.
This is because the file size of the article store is much larger than the file sizes of all the prefs and reading list/archives/etc. combined,
so having it in a flat file would drastically slow down the application.
Instead, the files are saved to disk and are not read until the user clicks on an entry and wants to view it offline.
Offline mode
Offline mode requires many changes to the architecture as a whole.
The main point of conflict is that we need to store many articles to disk
but not keep their full contents in memory.
This means the full state is no longer stored within EntryBook anymore.
The following sections describe
the design decisions made to support offline mode.
Architectural changes
Removing undo/redo feature
The undo/redo feature assumes that a ReadOnlyEntryBook
contains all the information in an EntryBook
and that it can be used to restore an EntryBook to any prior state.
However, this assumption no longer holds if we were to store articles on disk
but not keep them in memory.
Instead of modifying the design of undo/redo, we decided to simply remove the feature as it was not a core feature required in our user stories.
Moving Storage behind Model
Because we now have state that exists on the disk but not in memory, we want to reflect this as well in the design.
State belongs in the Model abstraction layer,
but at the same time disk access belongs inside Storage.
We decided it was not wise to keep these too decoupled,
and instead we moved Storage under Model
to improve cohesion at the expense of worsening coupling.
Current implementation
After the architectural changes were made, there are a few design considerations that needed to be made:
Network design
As we need to save the articles to disk,
we first need a way to obtain said articles from the Internet.
This is described in section Network design
Interfacing with BrowserPanel
Currently, Storage provides a method that returns an Optional<Path>,
which will contain the path to the offline copy if it exists.
This is because BrowserPanel works by displaying URLs in a WebView.
Thus, by directly supplying the path,
it’s better than reading the content into a String,
in case there are any encoding issues.
Storage model
When saving articles to disk, we need to do so in a way that performs well. This is described in section [Design-Storage]
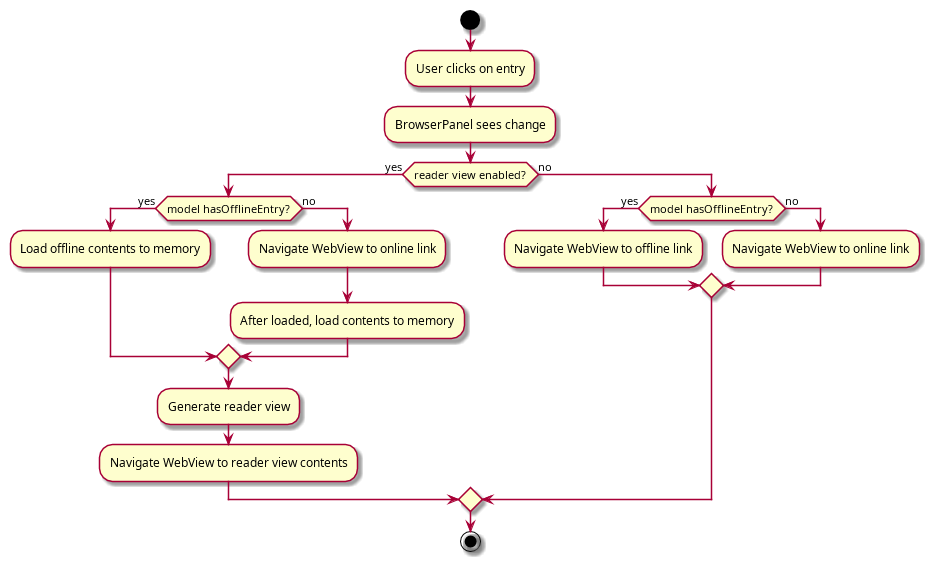
Viewing an entry with offline mode
As an example, what happens when viewing an entry with offline mode enabled? This is summarised by the activity diagram below: